Designing a Data Schema
Selecting Appropriate Storage Technologies in GCP

Schemas are for structured and semi-structured data. Structured data is typically stored in relational databases, whereas semi-structured data is stored in NoSQL databases.
This article evaluates the various consideration that data engineers examine when designing a data schema. By the end of this article, you should have a better grasp of what comes into consideration when designing a schema.
Once you've decided on whatever type of storage technology to utilise, you might need to develop a schema that will provide the best storage and retrieval option since the schema affects how we save and retrieve data.
GCP offers a variety of database services. They are all meant to address some specific circumstances, but not all of them. As a result, understanding how a particular database works and why it is suitable for your use case is necessary for performance.
Relational Database Design
Relational databases are suitable for consistency, structured data (fixed schema), transactions and joins.
Relational databases are of two types, and their schema design considerations vary.
Below are the two primary types of relational databases:
Online analytical processing (OLAP)
Online transaction processing (OLTP)
Online Analytical Processing (OLAP)
Online analytical processing systems allow users to analyse data from many databases simultaneously. It is built on a multidimensional data schema and helps the user to query data.
OLAP queries are for trend analysis, financial reporting, sales prediction, account budgeting, and other types of planning.
An analyst may then use these multidimensional databases to execute five sorts of OLAP operations:
Slice: This allows a data analyst to exhibit a single source of insight, for example, customers in the previous year.
Dice: This enables analysts to assess data from several dimensions, for example, "Customer who purchased product X online in the previous month."
Roll-up: This technique encapsulates data with its dimensions and is known as aggregation or drill-up.
Drill-down: This enables analysts to explore the data's aspects in greater depth (i.e. from summary to more individual details)
Pivot: Switching the data axes or dimensions may give analysts a fresh perspective on the data.
Online transaction processing (OLTP)
Online transaction processes (OLTP) are optimised for day-to-day transaction workflows and are often normalised. In addition, it allows for carrying out several parallel transactions.
A three-layer design is mainly used in an OLTP system. It generally consists of a presentation layer, a business logic layer, and a data storage layer. The presentation layer is where the transaction is initiated by a human or is created by the system. The logic layer comprises policies that check the transactions and guarantee the completeness of the data. The transactions and their associated data are then stored in the data storage layer.
The following are the key features of an online transaction processing system:
ACID: This ensures a transaction is recorded only when each step in a transaction is complete and documented. The entire transaction must be terminated and all the steps removed from the system in the event of a single step-related violation. ACID is an acronym for atomic, consistent, isolated, and durable (ACID).
Availability.
Scale.
Concurrency.
High Throughput
NoSQL Database Design
Contrary to RDBMS, NoSQL databases are not well defined, and no central data modelling technique applies to all NoSQL databases.
NoSQL databases are suitable for high performance, unstructured data (flexible schema), availability and easy scalability.
The four varieties of NoSQL databases on GCP are:
Graph
Document
Wide column
Key-value
Graph
The foundation of graph databases represents elements and connections as nodes and links in a graph or network.
The graph connects the data items in the database to a network of nodes and edges, with the edges indicating the node’s connections. This relationship enable data stored in a graph database to be immediately tied together and mostly accessible with a single action.
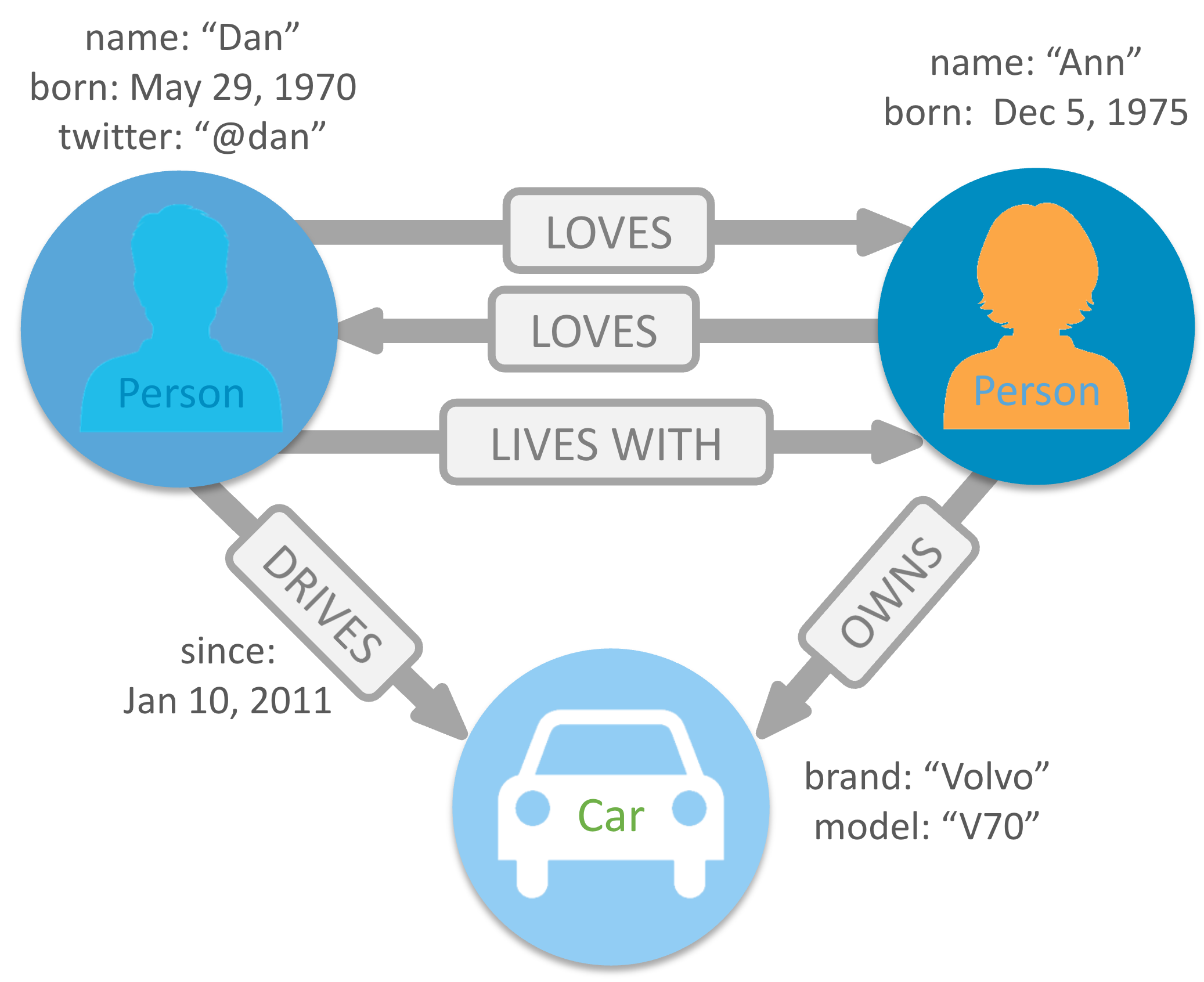
Data may be accessed from a graph database using Graph query programming languages such as:
Gremlin: Part of Apache TinkerPop
SPARQL: Used in RDF databases
Cypher Query Language (Cypher): SQL-like declarative language for Neo4j
An example of a Cypher query used to retrieve information from the image above is as follows;
MATCH (n:Person)-[:LOVES]-(a)
MATCH (n)-[:LIVES WITH]-()-[:DRIVES]-(b) RETURN n, b
Although GCP lacks a managed graph database, Bigtable is fit as the storage backend for HGraphDB and JanusGraph. Also, you can use Neo4j AuraDB on Google Cloud from GCP Marketplace.
Document
Document database uses sophisticated data schemas, known as documents, to make values visible and able to be queried. Each piece of data is characterised as a document and is typically stored in JSON or XML format.
The following are some primary use cases for document databases:
Datasets and metadata for web and mobile apps (JSON, XML, RESTful APIs, unstructured data)
App and process event logging - individual event occurrence is defined by a new document.
Online blogs - posts, comments, favourites, or activities- are characterised as documents.
Below is an example of a document database representation of Ishola's profile with social media details attached
{ "_id": "engrkrooozy", "firstName": "Ishola", "middleName": "krooozy", "lastName": "Olawale", "email": "ishola.krooozy@example.com", "unit": ["protocol", "technical"], "socialMediaDetails": [ { "platform": "instagram", "username": "engr_krooozy" }, { "platform": "twitter", "username": "@engrkrooozy" } ] }
Firestore is a GCP serverless document database that can quickly scale to meet your needs. On the other hand, Google's Datastore is a managed document database service offered by GCP.
If you intend to maintain your document database, MongoDB, OrientDB, Terrastore, CouchDB, and RavenDB are more choices. In addition, you can explore some of the above document databases on the Google cloud marketplace.
Wide column
Google's 'Bigtable inspired the wide-column database. It stores data in columns or groups of columns.
Column 'families' are several rows with unique keys belonging to one or more columns. Rows in a column family are not required to share the same columns.
Since data is in columnar format, searches for a specific value in a column run very rapidly because the entire column can be read and retrieved quickly.
The following are some primary use cases for a wide-column database:
Excellent for handling vast amounts of sparse data.
Column databases may be distributed over node clusters.
Search using a single key.
Columns may have a time-to-live (TTL) parameter - which is helpful for data having an expiration date.
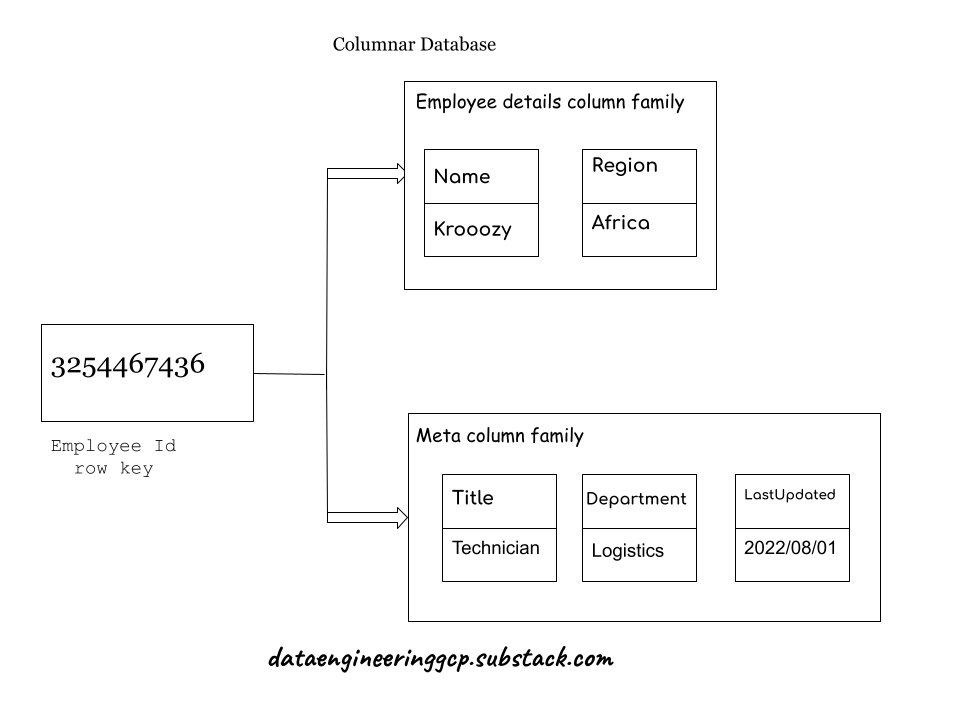
Bigtable is Google Cloud Platform's managed wide-column database. Since Bigtable provides an HBase interface, it is also a viable choice for migrating on-premises Hadoop HBase databases to a managed DB.
Apache Cassandra, ScyllaDB and Apache HBase are more choices if you intend to maintain your document database. In addition, you can explore some of the above wide column databases on the Google cloud marketplace.
Key-value
A key-value database binds keys to values, which can be of any data. Keys are for retrieving values.
It represents a key-value by a hashmap and is ideal for basic CRUD operations (Create, Read, Update and Delete).
The following are some primary use cases for a key-value database:
CRUD operations on non-linked data - data from sessions and retrieval for web applications.
In-app storage of users' details and activities.
Data from online retail carts.
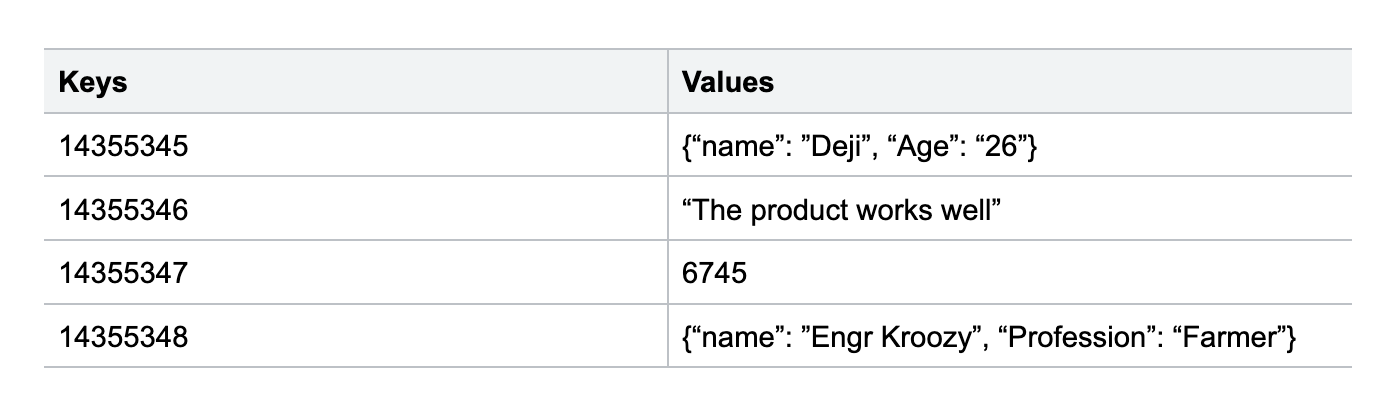
Cloud Memorystore is a fully managed key-value datastore built on Redis. It offers minimal latency with scalable, secure, and highly available in-memory Redis and Memcached services.
Redis, Memcached, Aerospike and Riak are a few other options if you maintain your key-value database. In addition, you can explore some of the above key-value databases on the Google cloud marketplace.
Final Thoughts
NoSQL is not a replacement for RDBMS since they serve distinct purposes. RDBMS or NoSQL databases should be based on a careful case-by-case analysis to optimise performance and flexibility.