Getting to know Cloud Spanner
Building and operationalizing storage systems.

Cloud Spanner is a fully managed relational, infinitely scalable, strongly consistent database with up to 99.999% dependability.
Cloud Spanner delivers strong consistency across primary and secondary indexes, ensuring that all concurrent processes view the same database state. It also enhances performance by automatically sharding data based on request traffic and data size, allowing you to focus entirely on growing your business.
Spanner also offers SQL support, enabling users to use ALTER statements for schema modifications. It comes with managed instances (regional and multi-region) with high availability via explicit, concurrent, inherent data replication.
Setting Up Cloud Spanner
Cloud Spanner deployment is comparable to Cloud SQL settings.
An instance's pricing is influenced by whether it is regional or multi-regional and the number of nodes. For example, a single node in a regional instance Lowa (us-central1) presently costs $0.90 per hour, while a multi-regional instance in North America, Europe, and Asia 3 (nam-eur-asia3) costs $9.00 per hour.
Your workload needs will typically influence how many nodes you choose. Google advises provisioning adequate computing power to keep high-priority total CPU utilization below 45% in each region for multi-regional instances and below 65% in regional instances.
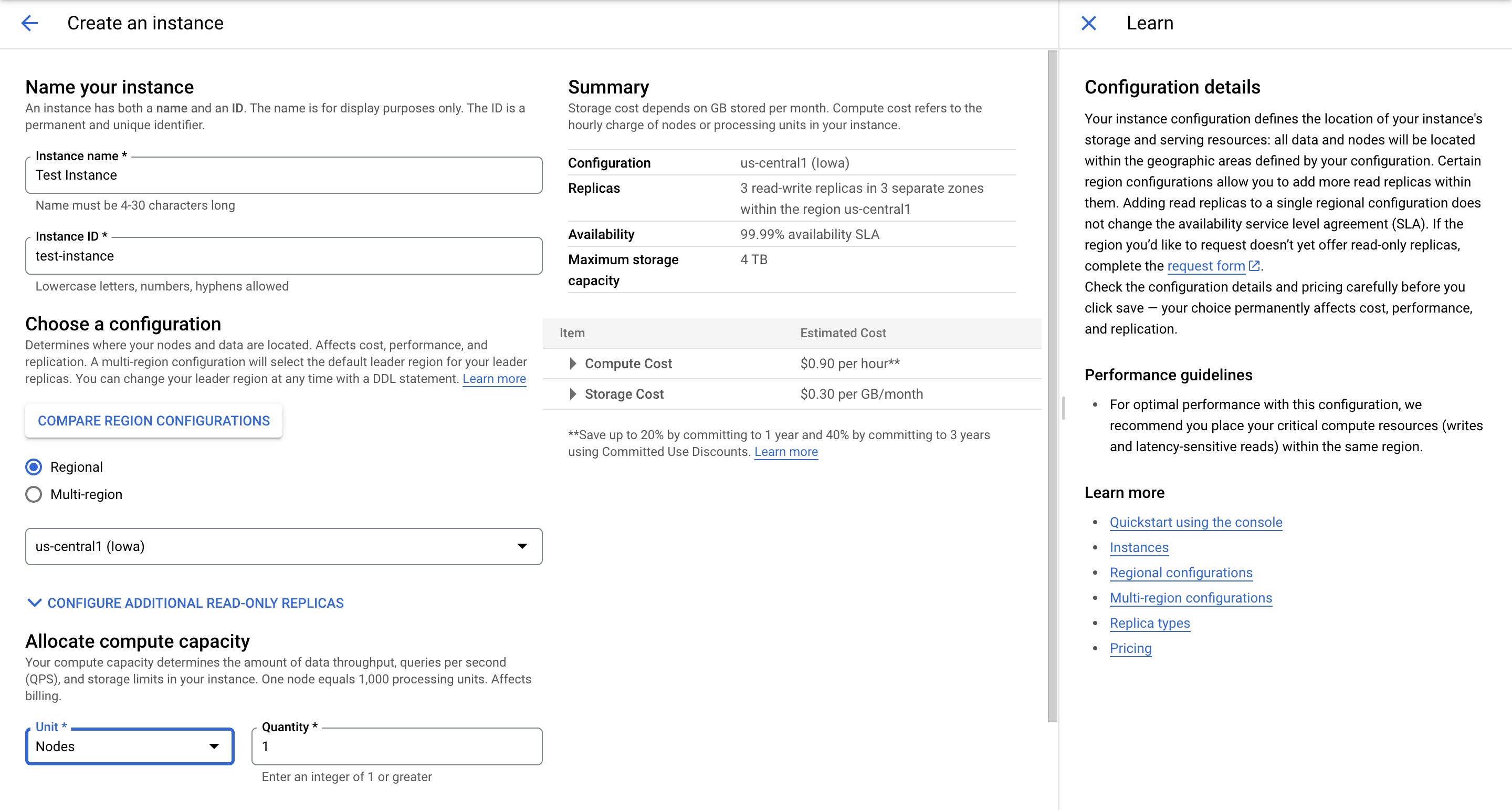
Spanner sets storage limitations per the computation capability of the instance to ensure high availability and minimal latency while accessing a database. For example, cloud Spanner allocates 409.6 GB of data per 100 processing units and 4TB of data per node or 1000 processing units in the database.
How Cloud Spanner Replicates Data
Cloud Spanner keeps several copies (replicas) of data rows in different locations. You may read from any copy to retrieve the most recent data in a block because Spanner uses fully concurrent replication.
Writing data into Cloud Spanner is tricky because of its distributed architecture. As a result, to maintain coherency across all replicas, cloud Spanner uses a voting process to decide on write operations.
Each database split is replicated using Spanner. A split contains a collection of continuous rows sorted by primary key. The replica technically stores all data in a split collectively, and Spanner feeds each replica from a unique failure zone.
Paxos is used to duplicate and keep a collection of splits. One replica is picked to act as the leader for each Paxos replica set. Lead replicas handle writes. Some of the benefits of read replicas are the availability of data and simplified application development.
Spanner has three replicas: Read-write replicas, Read-only replicas and Witness replicas.
Multi-regional instances may leverage all replicas, whereas regional instances leverage read-only replicas. Read-write replicas keep complete duplicates of the data, support read operations, and partake in write operation voting. Replicas that only support read operations and keep complete copies of the data can not partake in write operation voting. Likewise, witness replicas can not maintain complete copies of the data while engaging in write votes. Thus, witness replicas help ensure a quorum during write operation votes.
Database Design in Cloud Spanner.
A good database design avoids hotspots, a scenario when several read or write actions take place on a single node instead of simultaneously across various nodes. Consider the following when choosing a primary key for your database to avoid hotspots:
In a table with high writes, avoid monotonically increasing or decreasing values.
Use descending order for timestamp-based keys.
By doing so, Cloud Spanner distributes writes equally among several nodes.
Normalization of relational databases typically demands the use of joins for data retrieval. For optimal performance and reduced processing time, take advantage of interleaving by establishing a parent-child connection between similar tables you may query together.
Best practices for data import and export
Using the Import and Export features, you can use Dataflow to transmit data in large volumes into or out of Cloud Spanner databases.
Avro or CSV files can be used by engineers to export a Cloud Spanner database to a Cloud Storage bucket. Likewise, you can import data in Avro or CSV files into a Cloud Spanner database.
Examples of use cases for data import and export are ingesting data for analytical operations, backup and archival and database duplication for experimental or production.
Yaseenali