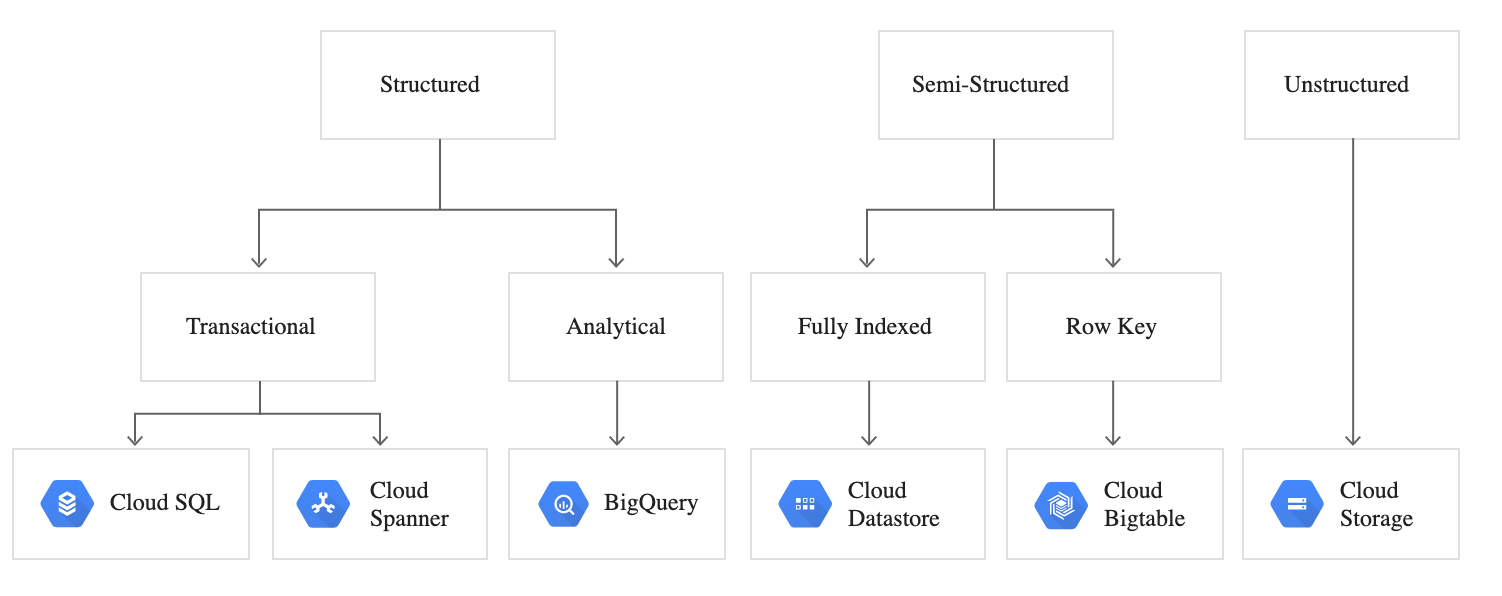
Types of Structure: Structured, Semi-Structured, and Unstructured
Selecting Appropriate Storage Technologies in GCP

Variety is the diversity of data sources, structures, and complexity.
The degree of change you anticipate in the data structure is another vital factor when selecting a storage technology.
This article analyses the different types of data structures. When choosing a storage technology, assessing how data is structured is helpful since it directly influences our choice of storage. By the end of this post, you should have a broader understanding of the different classifications of data structures and how they affect our decision when selecting an optimum storage technique.
There are three well-known classifications:
■ Structured
■ Semi-structured
■ Unstructured
These classifications are especially useful when selecting a database.
{kind=link}
Structured Data
Structured data should have a consistent model. For example, we may use tables containing rows and columns of data to represent structured data, wherein columns are descriptors or features, and rows are entries.
Structured data consist of client data such as names, addresses, credit card numbers, and other quantitative information. Structured data is simple to store and maintain in databases. Structured data may appear in one of the following scenarios:
Transactional / Operational Structured Data.
Analytical Structured Data.
Transactional Structured Data
Transactional Structured data refers to data generated by the daily activities of your business. They are frequently queried one row at a time.
Operational data is what you use to know the most recent information about anything in your company. For example, when displaying data about employee work hours, a company may look for tracking data from the employee’s Table.
Because we may access several columns from individual rows, it is best appropriate to store all row parameters in one data block. Thus, querying one data block will obtain all required information, a typical trend in transactional databases that leverage row-oriented storage, such as Cloud Spanner and Cloud SQL.
Analytical Structured Data
Analytical structured data refers to data that has been gathered and is ready to be queried and analysed for business insight.
Instead of capturing data from business operations, analytical data are majorly for making business choices.
When working with a product dataset in a data warehouse, a business analyst is curious to see how a savings product from last month contrasts with those from the same time last year.
The data mart generally has a single row for each product across each date, with the following entries: amount saved, total savings balance, average savings, average marginal savings, and total marginal savings. The analyst is primarily concerned with the overall monthly savings for each customer.
In this situation, the analyst would query many rows and just the necessary columns (date, product, and amount saved), which is more effective and suitable than querying the entire block for all rows.
This is more appropriate when dealing with analytical data. It is for this reason that BigQuery adopts a column-oriented storage technique.
Semi-Structured Data
Semi-structured data has some structure but does not adhere to a particular data model.
This type of data does not have a fixed or rigorous schema. i.e. can differ from one instance to the next.
The two primary ways of storing semi-structured data in a database and their respective data retrieval format are:
Documents (Fully Indexed)
Wide Columns (Row Key Access)
Fully Indexed, Semi-Structured Data
Document databases leverage indexes to quickly search by characteristics.
You might define indexes in Cloud Firestore for each data feature and a combination of features. They are optimised to handle how data is retrieved.
If you anticipate customers searching for books by title and publisher, you should define a title and publisher index. Likewise, if you expect customers looking for consumables by manufacturer, you should define a manufacturer index.
The proportion of storage used might be substantially higher by creating several indexes. Commonly, the overall index storage exceeds the amount of storage required to store documents. However, adding more indexes might affect the efficiency of insert, update, and delete operations since the database must update the indexes to accommodate those changes.
Row Key Access, Semi-Structured Data
Wide-column databases structures data so that rows with identical row keys are adjacent. Like primary keys in relational databases, queries use row keys to retrieve data.
It's crucial to understand that wide-column databases such as Bigtable are optimised for high-volume writes and low-latency reads which might result in data duplication.
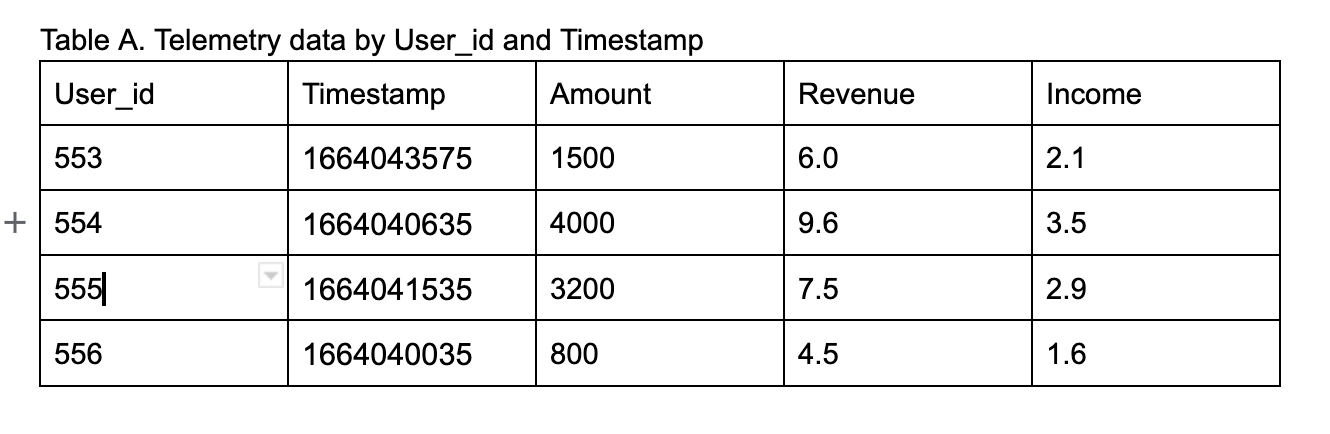
Let's explore telemetry data stored in a wide-column database. Table A above contains data by transaction id and timestamp. Subsequent rows may have a similar user_id but different associated timestamps, with both defining the row key.
Table A is optimised to fetch results for queries that retrieve data by User_id and then timestamp. It is not appropriate for spooling data by time, for example, details of transactions in the last 30 minutes. Wide-column databases duplicate data using another row key pattern, as shown in Table B, instead of defining an index on the timestamp.
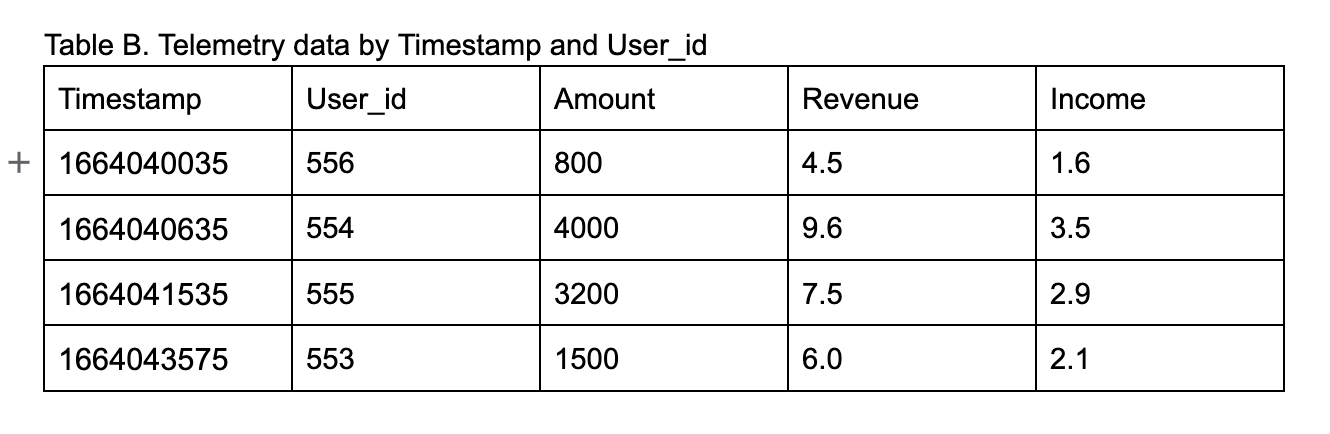
Table B is optimised to retrieve data for time-range queries.
Unstructured Data
Unstructured data refers to data that does not fit a pre-defined data schema or is not in a pre-defined pattern. Unlike other structures, they cannot fit into a tabular format (row and column) or a relational database.
Unstructured data lacks order and is typically qualitative. Word processing documents, audio files, photos, and videos are all unstructured data. Some unstructured data can be stored in a BLOB (Binary Large Objects) format. Music, images and multimedia data may all be stored as BLOBs.
Examples of unstructured data.
PowerPoint slides and Word documents
Images
Videos
Text files in human languages, i.e. Memos, reports, etc.
You may realise that the examples above have some individual structures, like Text files in human languages may have some ordered language syntax and chapter arrangement. However, these structures are not relevant to how they are stored, which makes them unstructured data.